
Định luật Matching và cách não bộ phân bổ sự chú ý: Khi quá trình nhận thức tuân theo quy luật lựa chọn
Tóm tắt
Định luật Matching mô tả sự phân bổ hành vi trong nhiều bối cảnh khác nhau, bao gồm các buồng thí nghiệm trong phòng thí nghiệm, các khu vực tìm kiếm thức ăn trong rừng, các sân thể thao và các trò chơi trên bàn. Điều đáng chú ý là Matching vẫn tồn tại trong những bối cảnh mà các phân tích kinh tế dự đoán những phân bố hành vi rất khác, và nó cũng khác một cách có hệ thống so với “probability matching” (sự tương xứng xác suất). Chúng tôi kiểm tra xem liệu định luật Matching có mô tả sự phân bổ của các quá trình nhận thức tiềm ẩn hay không. Sáu mươi bốn người tham gia quan sát hai kích thích nhỏ, được sắp xếp theo chiều dọc và nằm gần nhau, tạo thành một hình ảnh nằm trong vùng fovea. Một phiên bản theo từng lần thử của các điều kiện phần thưởng được sử dụng trong các thí nghiệm Matching Law quyết định kích thích nào là mục tiêu. Ví dụ, trong một điều kiện, kích thích phía trên là mục tiêu thường xuyên hơn ba lần so với kích thích phía dưới. Tuy nhiên, thời gian hiển thị của các kích thích được điều chỉnh riêng cho từng người tham gia sao cho họ không thể sử dụng thông tin từ cả hai kích thích mặc dù một thí nghiệm theo dõi mắt khác xác nhận rằng họ nhìn thấy cả hai. Hàm ý của sự hạn chế này là người tham gia phải quyết định sẽ chú ý vào kích thích nào trước mỗi lần thử. Cơ sở khách quan duy nhất cho quyết định này là tần suất tương đối mà một kích thích là mục tiêu. Định luật matching dự đoán mối tương quan giữa tần suất tương đối mà một kích thích là mục tiêu và tỷ lệ số lần thử mà nó được chú ý. Kết quả ủng hộ nhận định rằng định luật matching là một nguyên tắc lựa chọn tổng quát - một nguyên tắc mô tả sự phân bổ của các quá trình tinh thần tiềm ẩn cũng như các phản ứng hành vi quan sát được.
Ngôn ngữ đời thường phân biệt giữa suy nghĩ và hành vi. Các nhà tâm lý học cũng vậy. Các chức danh nghề nghiệp, giáo trình và bài báo khoa học của họ phản ánh sự phân chia giữa tâm lý học nhận thức và tâm lý học hành vi. Tuy nhiên, suy nghĩ và hành vi có một đặc điểm cơ bản chung: cả hai đều có năng lực hạn chế. Tại bất kỳ thời điểm nào, có nhiều thứ cần xem xét hơn khả năng có thể xem xét, và có nhiều việc cần làm hơn khả năng có thể thực hiện. Theo định nghĩa, chú ý và lựa chọn đều mang tính chọn lọc, và trong cả hai lĩnh vực, phần thưởng đóng vai trò quan trọng trong việc xác định cái gì được chọn. Thí nghiệm của chúng tôi xuất phát từ những quan sát này. Nó kiểm tra liệu một nguyên tắc định lượng hướng dẫn lựa chọn trong nhiều điều kiện khác nhau cũng có hướng dẫn việc phân bổ nhận thức hay không. Nguyên tắc lựa chọn này được gọi là “định luật Matching” (Herrnstein, 1970; Herrnstein, Rachlin, & Laibson, 1997), và nhiệm vụ thí nghiệm mà chúng tôi sử dụng để kiểm tra matching liên quan đến các sự chuyển đổi chú ý tiềm ẩn giữa hai kích thích thị giác nhỏ, nằm gần nhau. Không có phần thưởng rõ ràng trong thí nghiệm; thay vào đó, có một tỷ lệ khách quan của các mục tiêu đúng và, tất nhiên, là đánh giá của người tham gia về việc họ đã trả lời đúng hay chưa. Phân tích của chúng tôi chủ yếu dựa vào yếu tố đầu tiên. Do đó, thí nghiệm của chúng tôi kiểm tra liệu định luật matching có cung cấp một mô tả định lượng chính xác về mối quan hệ giữa các sự chuyển đổi chú ý tiềm ẩn và tần suất được sắp đặt của các câu trả lời đúng hay không. Ở mức tổng quát hơn, thí nghiệm kiểm tra liệu định luật Matching có áp dụng cho việc phân bổ các quá trình tinh thần có hạn cũng như đối với các quá trình hành vi có hạn hay không. Theo hiểu biết của chúng tôi, đây là thí nghiệm đầu tiên đánh giá câu hỏi này.
Định luật Matching
Theo định luật Matching, phân bố tổng thể của các lựa chọn xấp xỉ phân bố tổng thể của phần thưởng. Ví dụ, nếu chỉ có hai lựa chọn, như trong nhiều nghiên cứu thực nghiệm, thì:
B1/(B1 + B2) ≈ R1/(R1 + R2)
trong đó Bi là tần suất của các lựa chọn 1 và 2, và Ri là tần suất của các phần thưởng liên quan đến các lựa chọn 1 và 2. Mặc dù đơn giản, phương trình này có phạm vi áp dụng rộng. Chim bồ câu là đối tượng trong thí nghiệm ban đầu (Herrnstein, 1970). Trong các thí nghiệm sau đó, Matching được quan sát thấy ở chuột, khỉ, bò, con người, và thậm chí cả côn trùng. Các bối cảnh bao gồm hầu hết nhưng không giới hạn ở việc nhấn cần gạt trong buồng thí nghiệm, các nhiệm vụ phát hiện tín hiệu, tìm kiếm thức ăn trong môi trường tự nhiên, các nước đi mở đầu trong cờ vua, các cú ném hai điểm so với ba điểm trong bóng rổ đại học, và các tình huống sau touchdown trong NFL. Các phần thưởng đi kèm nhưng không giới hạn ở thức ăn, tiền, kích thích não, ma túy, rượu và sự chấp thuận xã hội. Tính tổng quát cao này giải thích vì sao phương trình này thường được gọi là một “định luật”. Tuy nhiên, trong hàng trăm nghiên cứu về định luật matching, biến phụ thuộc luôn là một hoạt động có thể quan sát được, một hành động có thể được ghi hình.
Một quy trình để định lượng sự phân bổ chú ý tiềm ẩn
Thí nghiệm hiện tại được xây dựng dựa trên hai nghiên cứu trước đó từ phòng thí nghiệm của chúng tôi (Heyman, Grisanzio, & Liang, 2016; Heyman, Montemayor, & Grisanzio, 2017). Trong các nghiên cứu này, một màn hình máy tính hiển thị hai kích thích nhỏ, nằm gần nhau. Một xác suất cố định quyết định kích thích nào là mục tiêu (tương tự như trong các nghiên cứu về Probability Matching), và do đó nhiệm vụ của người tham gia là báo cáo nội dung của kích thích đó. Mặc dù hai kích thích tạo thành một hình ảnh không vượt quá kích thước của vùng fovea, điều mà chúng tôi đã xác nhận trong một nghiên cứu theo dõi mắt, thời gian hiển thị của kích thích được điều chỉnh riêng cho từng người tham gia sao cho họ có thể báo cáo chính xác một kích thích, nhưng không thể báo cáo cả hai. Nói cách khác, người tham gia “nhìn thấy” cả hai kích thích nhưng chỉ có thể xác định nội dung của một trong số đó.
Chúng tôi đã phát triển một mô hình toán học cho quy trình này cho phép xác định kích thích mà họ thực sự đã chú ý. Phương trình bao gồm một thành phần cho việc đoán đúng, và được thiết lập sao cho nghiệm của phương trình là tỷ lệ số lần thử mà người tham gia đã chú ý đến kích thích mục tiêu. Nói cách khác, chúng tôi tính toán sự phân bổ của chú ý tiềm ẩn.
Một đặc điểm quan trọng của quy trình (và mô hình toán học của nó) là xác suất mà hai kích thích cung cấp thông tin cần thiết cho một phản hồi đúng có tổng bằng 1.0 trong mỗi lần thử. Tuy nhiên, trong hầu hết các thí nghiệm về định luật matching, hai hoặc nhiều bộ đếm thời gian độc lập, mỗi bộ gắn với một lựa chọn, quyết định khi nào một lựa chọn tạo ra phần thưởng. Tại bất kỳ thời điểm nào, một, cả hai hoặc không có lựa chọn nào cung cấp quyền truy cập vào phần thưởng, và các xác suất này tăng theo thời gian kể từ lần nhận phần thưởng gần nhất. Chúng tôi đã điều chỉnh cách tiếp cận xác suất của các nghiên cứu trước đó để mô phỏng các điều kiện củng cố theo thời gian, dựa trên tần suất, trong các nghiên cứu về định luật matching.
Giống như trong các nghiên cứu về định luật Matching, trong bất kỳ lần thử nào, một kích thích, cả hai kích thích hoặc không có kích thích nào là mục tiêu. Mặc dù sử dụng quy trình theo từng lần thử, một cơ chế xác suất giống như “đồng hồ” quyết định liệu một kích thích có phải là mục tiêu hay không. Ví dụ, giống như trong các nghiên cứu Matching Law, khả năng một kích thích là mục tiêu tăng theo số lần thử kể từ lần trả lời đúng gần nhất.
Phần thưởng và sự chú ý
Trong khoảng 20 năm qua, đã có sự quan tâm ngày càng tăng đối với mức độ và cách thức mà giá trị phần thưởng của kích thích ảnh hưởng đến sự chú ý. Trong một ví dụ đặc biệt đáng chú ý, giá trị phần thưởng làm suy yếu hiện tượng “Attentional Blink” đã được nghiên cứu rộng rãi, và nhiều nghiên cứu cho thấy rằng các kích thích dự đoán phần thưởng có thể kiểm soát sự chú ý theo cách tương tự như các đặc điểm vật lý nổi bật như sự xuất hiện đột ngột hoặc sự tương phản màu sắc mạnh.
Trong một tổng quan về lĩnh vực này, Chelazzi và các đồng nghiệp kết luận rằng có vẻ như nghịch lý khi các nguyên lý học tập được phát triển để giải thích hành vi có thể quan sát được lại phù hợp để giải thích các thay đổi trong ưu tiên chú ý dựa trên phần thưởng. Tuy nhiên, cũng có sự khác biệt đáng chú ý giữa các nghiên cứu về phần thưởng và chú ý so với các nghiên cứu hành vi truyền thống. Những khác biệt này bao gồm sự quan tâm mạnh mẽ đến các tương quan thần kinh của chú ý và sự quan tâm đến cách các nguồn khác nhau của độ nổi bật kích thích kết hợp để định hướng sự chú ý.
Các dự đoán
Chúng tôi kiểm tra ba giả thuyết định lượng. Thứ nhất, định luật Matching sẽ dự đoán sự phân bổ nhận thức tốt tương tự như cách nó dự đoán phân bố lựa chọn trong các nghiên cứu hành vi. Thứ hai, chúng tôi dự đoán rằng các sự chuyển đổi chú ý giữa các lần thử sẽ thay đổi có hệ thống như một hàm của sự phân bổ tổng thể của chú ý, tương tự với mối quan hệ giữa những thay đổi tức thời trong sở thích và sở thích tổng thể trong các thí nghiệm hành vi. Thứ ba, dựa trên các nghiên cứu trước đây của chúng tôi, chúng tôi dự đoán rằng trong những lần thử mà người tham gia chú ý đến kích thích cung cấp thông tin cần thiết cho một phản hồi đúng, họ sẽ chọn câu trả lời đúng ít nhất 90% thời gian, trong khi trong những lần thử mà họ chú ý đến kích thích không cung cấp thông tin cần thiết, họ sẽ thực hiện ở mức ngẫu nhiên, trong thí nghiệm này là 14.3%.
Một lưu ý là cần thiết. Quy trình và các phép đo của chúng tôi cho phép tồn tại nhiều “điểm nghẽn” nhận thức. Một kích thích có thể để lại dấu vết ban đầu yếu hơn, tạo ra mã hóa yếu hơn, hoặc trong quá trình xử lý thông tin của kích thích được chú ý, dấu vết ban đầu của kích thích còn lại có thể đã phai mờ khỏi trí nhớ. Đây không phải là các khả năng loại trừ lẫn nhau cũng như không phải là danh sách đầy đủ. Khi chúng tôi sử dụng từ “chú ý”, chúng tôi đang đề cập đến sự phân bổ có chọn lọc của tài nguyên nhận thức, có thể bao gồm hoặc không bao gồm các quá trình nhận thức–tri giác do nhiệm vụ thí nghiệm tạo ra.
Phương pháp
Người tham gia
Chúng tôi kiểm tra 64 người tham gia. Mỗi người hoàn thành hai phiên thí nghiệm. Tuổi trung bình là 18.58 (SD = 1.54); 45 người là nữ. Trước khi bắt đầu thí nghiệm, người tham gia ký vào mẫu đồng ý theo quy định của Hội đồng Đạo đức của Boston College. Sau đó, người thực nghiệm đọc một bộ hướng dẫn ngắn (cũng được hiển thị lại trên màn hình khi bắt đầu nghiên cứu). Người tham gia nhận được tín chỉ học phần khi tham gia. Quy trình được Hội đồng Đạo đức của Boston College phê duyệt.
Số lượng người tham gia được xác định dựa trên nghiên cứu trước đó của chúng tôi sử dụng phiên bản tương tự của quy trình này. Thí nghiệm đó tạo ra kết quả có trật tự và có ý nghĩa thống kê với 41 người tham gia. Chúng tôi tăng số lượng người tham gia trong nghiên cứu hiện tại để phòng trường hợp các thay đổi trong quy trình dẫn đến kết quả biến động hơn.
Thiết bị
Thí nghiệm được thực hiện trên máy tính xách tay. Màn hình có kích thước 31.1 cm × 17.5 cm với độ phân giải 1366x768 pixel. Người tham gia ngồi ở khoảng cách tùy ý, dao động từ khoảng 43 cm đến 65 cm.
Định luật Matching dạng tham số
Dựa trên các thí nghiệm thế hệ đầu tiên về định luật matching, Baum (1974) đã đưa ra một phiên bản tổng quát hơn dưới dạng tỷ lệ của công thức ban đầu của Herrnstein. Phiên bản này bao gồm hai tham số tự do phản ánh các đặc điểm có hệ thống trong dữ liệu. Chúng tôi sử dụng phiên bản này để mô tả cách người tham gia phân bổ sự chú ý giữa hai kích thích.
Trong tọa độ logarit, phương trình trở thành dạng tuyến tính:
log(B1/B2) = log a + b log(R1/R2)
Theo nhiều nghiên cứu, tham số chệch (log a) đo sự bất đối xứng giữa các lựa chọn, ví dụ như thiên lệch vị trí hoặc khác biệt về phần thưởng, và hệ số dốc (b) phản ánh mức độ mà người tham gia phân biệt chính xác tỷ lệ phần thưởng. Trong hầu hết các thí nghiệm, tham số chệch khác 0 và người tham gia không phân biệt hoàn hảo giữa các tỷ lệ phần thưởng cạnh tranh.
Các đặc điểm chính của quy trình
Hình 1 minh họa quy trình thí nghiệm. Hình này cho thấy các màn hình khác nhau cấu thành một trial, thứ tự của chúng và thời lượng tương ứng.
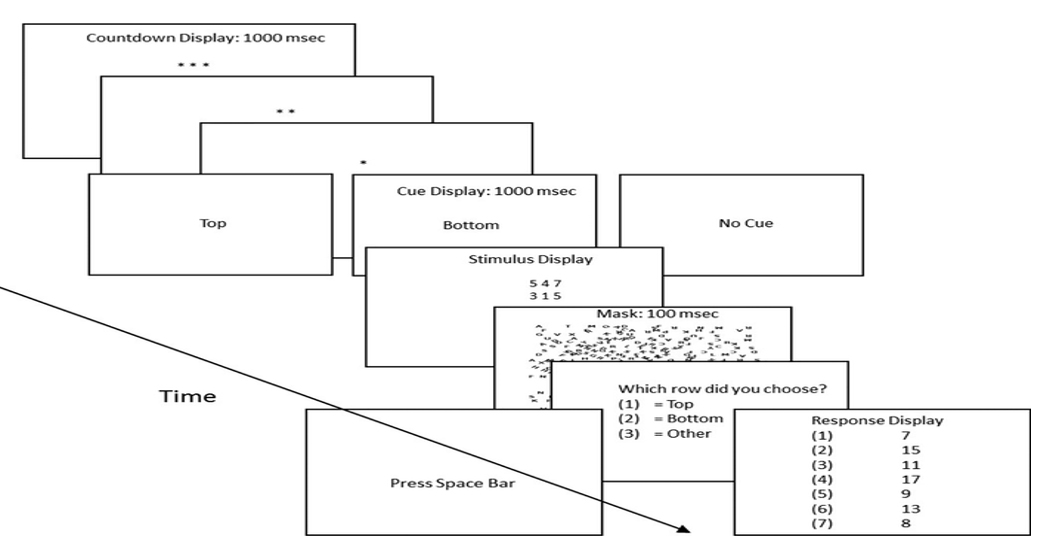
Nhiệm vụ của người tham gia là tìm con số trong màn hình trả lời tương ứng với tổng của ba chữ số ở hàng trên hoặc hàng dưới của màn hình kích thích. Ví dụ, trong Hình 1, ba chữ số của hàng dưới có tổng bằng 9, và số 9 là tổng thứ năm trong màn hình trả lời. Do đó, hàng dưới là kích thích mục tiêu và phím bàn phím mang nhãn “5” là phản ứng đúng.
Điểm khiến nhiệm vụ này trở nên khó là thời gian hiển thị của màn hình kích thích được điều chỉnh riêng cho từng người tham gia, sao cho họ chỉ có đủ thời gian để xác định tổng của một hàng, nhưng không đủ để xác định tổng của cả hai hàng (xem phần Quy trình hiệu chỉnh). Điều này có nghĩa là người tham gia phải quyết định sẽ chú ý vào kích thích nào trước khi mỗi trial bắt đầu.
Việc hàng trên hay hàng dưới là mục tiêu thay đổi theo xác suất. Các giá trị danh nghĩa (dưới dạng tỷ lệ tổng thể) là 1:9, 1:3, 1:1, 3:1 và 9:1. Ví dụ, trong điều kiện 1:9, kích thích phía dưới là mục tiêu thường xuyên hơn khoảng chín lần so với kích thích phía trên, và ngược lại trong điều kiện 9:1. Mỗi người tham gia chỉ trải nghiệm một tỷ lệ và hoàn thành hai phiên thí nghiệm với tỷ lệ đó. Người tham gia học nhiệm vụ khá nhanh, nhưng khác nhau về thời gian cần thiết để hiển thị kích thích nhằm có thể cộng đúng ba chữ số của một hàng.
Hiệu chỉnh thời gian hiển thị kích thích
Ở đầu mỗi phiên, người tham gia thực hiện một loạt các trial hiệu chỉnh. Mục tiêu là xác định thời gian hiển thị ngắn nhất vẫn cho phép trả lời đúng. Các trial hiệu chỉnh được tổ chức thành các khối gồm 4, 8 và 16 trial.
Trong ba phần tư số trial, một tín hiệu (cue) cho biết hàng trên hay hàng dưới là đúng, với xác suất 50% cho mỗi hàng. Tất cả người tham gia được kiểm tra với các thời gian hiển thị 600 ms, 400 ms, 300 ms, 200 ms và 150 ms theo thứ tự giảm dần trong các khối 4 trial.
Sau đó, thời gian hiển thị được điều chỉnh với bước nhỏ hơn và số trial trong mỗi khối được tăng lên 8 hoặc 16. Quá trình điều chỉnh tiếp tục cho đến khi người tham gia có thể xác định đúng đáp án trong ít nhất 87.5% các trial có cue, đồng thời có hiệu suất gần mức ngẫu nhiên trong các trial không có cue.
Cấu trúc của một trial
Sau khi hoàn tất giai đoạn hiệu chỉnh, phiên thí nghiệm chính bắt đầu. Mỗi trial bắt đầu bằng một giai đoạn chuẩn bị, được biểu thị bằng các dấu sao (*) biến mất với tốc độ 1 giây mỗi dấu, với khoảng nghỉ 100 ms giữa các màn hình.
Sau dấu sao cuối cùng, một màn hình kéo dài 1 giây hiển thị từ “Top” hoặc “Bottom” nếu là trial có cue, hoặc “No Cue” nếu không có cue. Tiếp theo là màn hình kích thích, hiển thị trong khoảng thời gian được xác định từ giai đoạn hiệu chỉnh (thường khoảng 130–140 ms).
Các chữ số trong màn hình kích thích được chọn từ tập hợp các số từ 1 đến 7 theo các ràng buộc sau:
- Một hàng không được chứa ba chữ số giống nhau
- Tổng của ba chữ số phải nằm trong khoảng từ 7 đến 17
- Mỗi giá trị tổng (11 giá trị có thể) xuất hiện với tần suất như nhau
- Tổng của hàng trên và hàng dưới phải khác nhau
Sau đó là màn hình “probe”, yêu cầu người tham gia báo cáo họ đã chú ý vào hàng trên, hàng dưới hoặc “khác”. Câu trả lời này được sử dụng như thước đo phân bổ chú ý (tính hợp lệ của báo cáo này được kiểm tra trong phần Kết quả).
Cuối cùng, nếu trial không có kích thích mục tiêu, màn hình hiển thị “Nhấn phím cách để tiếp tục”. Nếu có mục tiêu, màn hình trả lời sẽ hiển thị một cột gồm bảy giá trị tổng như trong Hình 1. Phản ứng của người tham gia được ghi nhận là đúng hoặc sai, và đồng thời khởi động giai đoạn đếm ngược cho trial tiếp theo.
Mô phỏng theo từng trial của hai bộ đếm biến thiên độc lập
Trong quy trình được sử dụng phổ biến nhất trong các nghiên cứu về lựa chọn theo định luật Matching, hai bộ đếm độc lập, mỗi bộ được liên kết với một phương án, và mỗi bộ chứa một chuỗi các khoảng thời gian có độ dài khác nhau, sẽ quyết định thời điểm một lựa chọn tạo ra phần thưởng.
Chúng tôi đã thiết lập một phiên bản theo từng trial của cơ chế này. Có hai trường hợp tổng quát: (1) các trial mà lịch sử của trial trước đó không ảnh hưởng (trường hợp phổ biến), và (2) các trial có sự “kế thừa” từ trial trước đó.
Mỗi kích thích được liên kết với một mảng gồm 30 số, trải dài từ 1 đến 30. Ở đầu mỗi trial, một số được chọn ngẫu nhiên (không hoàn lại) từ mỗi mảng. Nếu số được chọn đáp ứng tiêu chí để thiết lập một phản ứng đúng (được mô tả dưới đây), thì tổng của ba chữ số trong hàng tương ứng của màn hình kích thích sẽ xuất hiện như một trong bảy lựa chọn trên màn hình trả lời.
Trong điều kiện tỷ lệ 1:1, các số từ 1 đến 10 của Mảng 1 thiết lập rằng ba chữ số của hàng trên là kích thích mục tiêu, và các số từ 11 đến 20 của Mảng 2 thiết lập rằng ba chữ số của hàng dưới là kích thích mục tiêu. Các số khác không có tác dụng.
Trong các điều kiện 3:1, 1:3, 9:1 và 1:9, các chiến lược tương tự được sử dụng để xác định xem tổng của ba chữ số ở hàng trên hoặc hàng dưới có xuất hiện trong màn hình trả lời hay không - tức là xác định kích thích nào là mục tiêu.
Lưu ý rằng cách tiếp cận này tạo ra ba khả năng:
- Không có kích thích nào có đáp án tương ứng trong màn hình trả lời,
- Chỉ một trong hai kích thích có đáp án tương ứng, hoặc
- Cả hai kích thích đều có đáp án tương ứng.
Như đã đề cập, trong những trial mà quy trình không tạo ra kích thích mục tiêu, màn hình trả lời sẽ không xuất hiện, và thay vào đó hiển thị dòng chữ “Nhấn phím cách”. Điều này khởi động trial tiếp theo.
Trường hợp thứ hai xảy ra khi các mảng số đã thiết lập khả năng có một phản ứng đúng, nhưng người tham gia không chọn đúng tổng trong màn hình trả lời. Khi điều này xảy ra, kích thích mục tiêu vẫn tiếp tục là mục tiêu trong trial tiếp theo, nhưng hiển thị một tổ hợp chữ số mới. Đồng thời, kích thích còn lại vẫn có khả năng trở thành mục tiêu (giả sử trước đó nó chưa phải).
Mặc dù đây là một quy trình theo từng trial, cách mà cơ hội xuất hiện phản ứng đúng được thiết lập xấp xỉ với cách cơ hội nhận phần thưởng được thiết lập trong các thí nghiệm matching sử dụng lịch trình khoảng thời gian biến đổi (variable interval schedules).
Cụ thể:
- Thứ nhất, xác suất một kích thích trở thành mục tiêu tăng lên theo số lượng trial kể từ lần cuối cùng nó tạo ra một phản ứng đúng.
- Thứ hai, do thời lượng của giai đoạn đếm ngược và màn hình cue là cố định, tổng cộng 4.4 giây, nên xác suất một kích thích là mục tiêu cũng có một tương ứng về mặt thời gian. Ví dụ, trong điều kiện 1:1, mỗi mảng thiết lập xác suất tổng thể khoảng 0.33 để kích thích của nó là mục tiêu, tương ứng với khoảng thời gian kỳ vọng 13.2 giây kể từ lần đúng gần nhất. Trong các điều kiện 3:1 và 1:3, các khoảng thời gian trung bình tương ứng là 8.8 và 26.4 giây (và ngược lại). Trong các điều kiện 9:1 và 1:9, các khoảng thời gian trung bình là 7.4 và 66.6 giây (và ngược lại).
- Thứ ba, một khi một trong hai kích thích đã trở thành mục tiêu, nó sẽ tiếp tục là mục tiêu cho đến khi người tham gia xác định đúng nó trong màn hình trả lời.
Do đó, tương tự như trong các thí nghiệm matching trong phòng thí nghiệm, xác suất một kích thích là mục tiêu tăng theo thời gian, và khi đã trở thành mục tiêu, nó sẽ duy trì trạng thái đó cho đến khi được xác định chính xác.
Cấu trúc phiên thí nghiệm
Mỗi phiên thí nghiệm gồm 132 trial, trong đó có 22 trial có cue và 110 trial không có cue.
Trong số các trial có cue, 11 trial xuất hiện trong nửa đầu của phiên. Sau trial thứ 66, người tham gia có thể nghỉ giải lao tối đa 3 phút.
Mục đích của việc đưa vào các trial có cue trong phiên thí nghiệm là để kiểm tra xem quy trình hiệu chỉnh có cung cấp đủ thời gian để người tham gia cộng chính xác ba chữ số khi họ biết trước kích thích nào là mục tiêu hay không và từ đó suy ra liệu họ có đủ thời gian để trả lời đúng trong các trial không có cue khi họ đã chú ý đúng vào kích thích mục tiêu hay chưa.
Trong các trial có cue, xác suất hàng trên và hàng dưới là mục tiêu là như nhau.
Những điểm khác biệt
Chúng tôi muốn chỉ ra ba đặc điểm của nghiên cứu hiện tại là không điển hình.
Thứ nhất, trong các nghiên cứu về định luật matching, các nhà nghiên cứu thường đánh giá mối quan hệ giữa tỷ lệ lựa chọn và tỷ lệ phần thưởng thu được. Tuy nhiên, tỷ lệ lựa chọn có thể ảnh hưởng đến tỷ lệ phần thưởng thu được. Ví dụ, nếu tất cả lựa chọn đều hướng về một nguồn phần thưởng, thì phân bổ lựa chọn sẽ hoàn toàn khớp với phân bổ phần thưởng (đều là 100%), nhưng khi đó sẽ không rõ biến độc lập là lựa chọn hay hậu quả của lựa chọn.
Do đó, cách tiếp cận của chúng tôi là đánh giá sự phân bổ chú ý như một hàm của số lượng trial được thiết lập theo thực nghiệm mà trong đó kích thích hàng trên là mục tiêu so với số lượng trial mà kích thích hàng dưới là mục tiêu. Điều này cung cấp một cách giải thích ít mơ hồ hơn và mang tính thông tin cao hơn về mối quan hệ giữa chú ý và phản ứng đúng.
Thứ hai, hệ quả của việc chú ý vào kích thích mục tiêu là một câu trả lời đúng (giả sử việc cộng ba chữ số được thực hiện chính xác). Các hướng dẫn giải thích thế nào là câu trả lời đúng, và người tham gia được yêu cầu đạt được càng nhiều câu trả lời đúng càng tốt. Tuy nhiên, quy trình không cung cấp phản hồi rõ ràng về việc câu trả lời có đúng hay không. Do đó, hậu quả của việc chú ý vào một kích thích - giống như chính sự chú ý - là mang tính ẩn.
Thứ ba, trong các nghiên cứu trước về chú ý, chúng tôi suy ra sự phân bổ chú ý và tỷ lệ đoán đúng bằng cách giải các phương trình tuyến tính và bậc hai mô hình hóa hiệu suất. Trong phiên bản hiện tại, chúng tôi đơn giản yêu cầu người tham gia báo cáo họ đã chú ý vào kích thích nào. Như được trình bày trong phần Kết quả, các báo cáo này là hợp lệ.
Kết quả
Chúng tôi tổng hợp kết quả theo đơn vị nửa phiên cho mỗi phiên trong hai phiên của mỗi trong năm điều kiện.
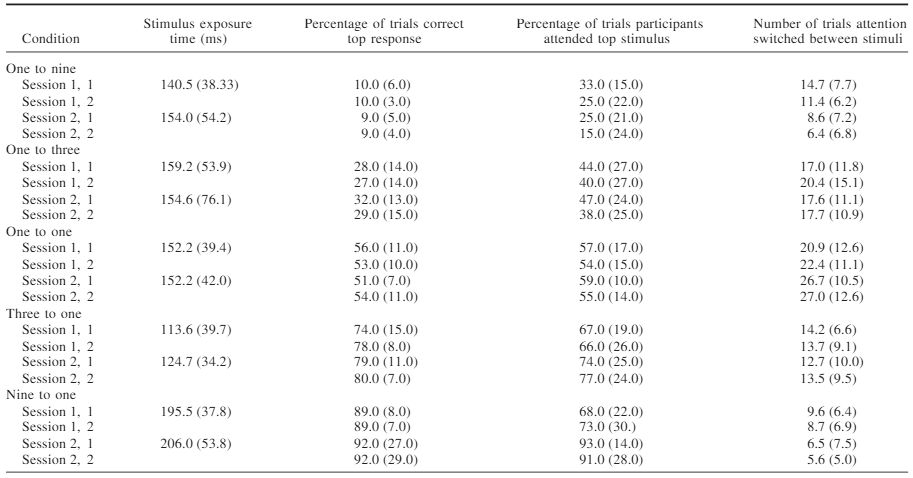
Bảng 1 trình bày các phát hiện chính. Trừ khi có ghi chú khác, các kết quả được trình bày là từ các trial không có cue.
Cột thứ hai hiển thị thời gian hiển thị trung bình, được xác định bởi quy trình hiệu chỉnh. Tính trung bình trên năm điều kiện, thời gian hiển thị trung bình trong phiên 1 là 156.7 ms (giá trị nhỏ nhất 70 ms và lớn nhất 370 ms), và trong phiên 2 là 150.2 ms (giá trị nhỏ nhất 50 ms và lớn nhất 275 ms).
Cột thứ ba hiển thị tỷ lệ phần trăm trung bình các trial mà người tham gia xác định đúng tổng của ba chữ số ở hàng trên.
Cột tiếp theo hiển thị tỷ lệ phần trăm các trial mà người tham gia chú ý vào hàng trên.
Cột cuối cùng hiển thị số lần trung bình mà chú ý chuyển từ kích thích này sang kích thích khác trong mỗi khối 55 trial.
Trong mỗi điều kiện, sự phân bổ chú ý dịch chuyển theo hướng gần hơn với tỷ lệ các trial mà kích thích hàng trên là mục tiêu. Xu hướng này được thể hiện rõ hơn trong Hình 2.
Tóm tắt các phát hiện chính về các thử nghiệm không có tín hiệu gợi ý.
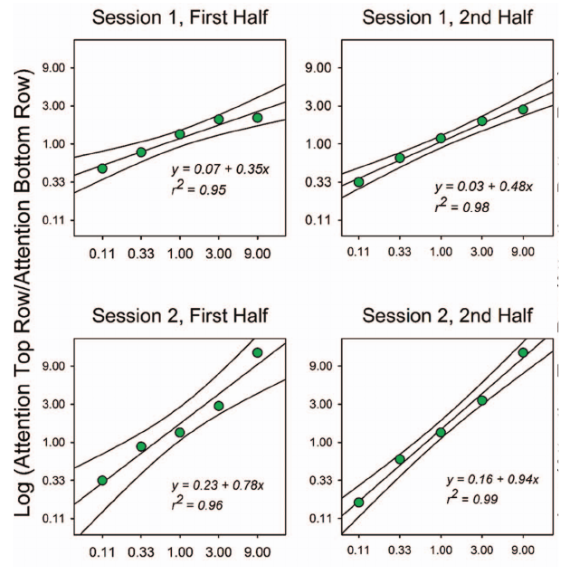
Tỷ lệ phân bổ sự chú ý theo số lần thử mà kích thích hàng đầu là mục tiêu so với số lần thử mà kích thích hàng dưới là mục tiêu (trong hệ tọa độ logarit). Các điểm dữ liệu là giá trị trung bình của nhóm, và các đường cong biểu thị khoảng tin cậy 95%. Các điểm cắt và độ dốc trong các phương trình là các tham số phù hợp nhất cho định luật khớp tổng quát.
Hình 2 biểu diễn kết quả dưới dạng tỷ lệ theo phương trình của định luật matching tổng quát. Trục hoành biểu thị tỷ lệ số lần kích thích hàng trên được thiết lập là mục tiêu so với hàng dưới. Các phương trình hiển thị hệ số chặn và độ dốc tốt nhất, cùng với độ phù hợp của mô hình.
Định luật matching dự đoán mối quan hệ giữa tỷ lệ được lập trình mà kích thích hàng trên và hàng dưới là mục tiêu và sự phân bổ chú ý giữa chúng. Độ dốc của đường hồi quy tăng dần theo kinh nghiệm với quy trình và tiến gần đến 1.0, tương tự như trong các nghiên cứu hành vi. Các hệ số chặn đều dương, cho thấy có thiên lệch hướng về kích thích hàng trên.
Hình 3 cho thấy tần suất chuyển đổi chú ý giữa hai kích thích theo từng trial như một hàm của sự phân bổ chú ý tổng thể. Kết quả cho thấy sự chuyển đổi chú ý xảy ra nhiều nhất trong điều kiện 1:1, ít nhất trong các điều kiện 1:9 và 9:1, và ở mức trung gian trong các điều kiện 3:1 và 1:3 — một mẫu hình tương tự với kết quả từ các nghiên cứu trên động vật.
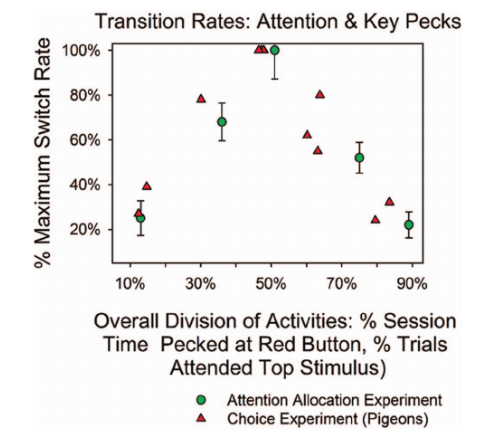
3. Các hình tròn tô đậm thể hiện sự thay đổi về sự chú ý từ nửa sau của phiên thứ hai. Các hình tam giác tô đậm thể hiện tỷ lệ chuyển đổi của bốn con chim bồ câu, được tính trung bình trên năm phiên cuối cùng của mỗi điều kiện. Kết quả từ thí nghiệm hiện tại là giá trị trung bình của nhóm, và các thanh lỗi biểu thị sai số chuẩn. Đối với dữ liệu từ nghiên cứu hiện tại, trục x thể hiện sự phân bổ tổng thể sự chú ý giữa hai kích thích (tính theo phần trăm). Đối với thí nghiệm chim bồ câu, trục x thể hiện sự phân bổ tổng thể thời gian dành cho mỗi nguồn thức ăn.
Các điều kiện tương tự tạo ra kết quả tương tự. Trong nghiên cứu này, sự chú ý chuyển đổi giữa hai kích thích thường xuyên nhất trong điều kiện tỷ lệ 1:1, ít thường xuyên nhất trong điều kiện 1:9 và 9:1, và ở tần suất trung bình trong điều kiện 3:1 và 1:3. Tương tự, chim bồ câu chuyển đổi giữa hai nguồn thức ăn thường xuyên nhất trong điều kiện thức ăn tỷ lệ 1:1, ít thường xuyên nhất trong điều kiện thức ăn tỷ lệ 1:9 và 9:1, và ở tần suất trung bình trong điều kiện 3:1 và 1:3.
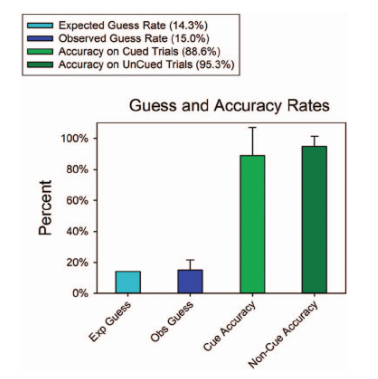
Hình 4 trình bày tỷ lệ phần trăm phản ứng đúng trong bốn điều kiện. Khi người tham gia không chú ý vào kích thích mục tiêu, tỷ lệ đúng xấp xỉ mức ngẫu nhiên (15% so với 14.3% kỳ vọng). Trong các trial có cue, tỷ lệ đúng là khoảng 89%, và trong các trial không có cue nhưng người tham gia chú ý đúng, tỷ lệ đúng đạt khoảng 95%. Điều này cho thấy người tham gia báo cáo chính xác nơi họ chú ý và ít mắc lỗi trong việc tính toán.
Các điều kiện tương tự tạo ra kết quả tương tự. Trong nghiên cứu này, sự chú ý chuyển đổi giữa hai kích thích thường xuyên nhất trong điều kiện tỷ lệ 1:1, ít thường xuyên nhất trong điều kiện 1:9 và 9:1, và ở tần suất trung bình trong điều kiện 3:1 và 1:3. Tương tự, chim bồ câu chuyển đổi giữa hai nguồn thức ăn thường xuyên nhất trong điều kiện thức ăn tỷ lệ 1:1, ít thường xuyên nhất trong điều kiện thức ăn tỷ lệ 1:9 và 9:1, và ở tần suất trung bình trong điều kiện 3:1 và 1:3.
Thảo luận
Phân bổ chú ý tổng thể và sự thay đổi chú ý theo từng trial
Hình 2 tóm tắt các kết quả ở mức tổng thể (molar). Kết quả cho thấy phương trình của định luật matching tổng quát mô tả sự phân bổ chú ý ít nhất cũng tốt như cách nó mô tả hành vi trong các thí nghiệm lựa chọn. Mô hình này giải thích từ 95% đến 99% phương sai trong các tỷ lệ phân bổ chú ý, và, tương tự như quan sát trong các nghiên cứu hành vi (ví dụ: Todorov và cộng sự, 1983), độ dốc của các hàm phù hợp — phản ánh mức độ ảnh hưởng của sự thay đổi trong tỷ lệ phần thưởng - tăng lên theo mức độ tiếp xúc với quy trình, tiến gần đến giá trị 1.0. Các hệ số chặn luôn lớn hơn 0.0, cho thấy tồn tại một thiên lệch ưu tiên kích thích ở hàng trên.
Hình 3 tóm tắt sự thay đổi chú ý theo từng trial, đồng thời so sánh với tỷ lệ chuyển đổi trong một nghiên cứu trên chim bồ câu. Như đã mô tả ở phần trước, quy trình trong thí nghiệm trên chim bồ câu tương tự với quy trình được sử dụng trong nghiên cứu hiện tại: tổng tỷ lệ tăng cường được lập trình là không đổi (tính cả hai lịch trình khoảng thời gian biến đổi), trong khi các tỷ lệ tương đối thay đổi trong khoảng từ 1:9 đến 9:1, giống như trong nghiên cứu này.
Trong cả hai thí nghiệm, tỷ lệ chuyển đổi đạt mức cao nhất khi sự phân bổ hoạt động giữa hai lựa chọn xấp xỉ 50:50, và sau đó giảm dần một cách đối xứng khi tỷ lệ lựa chọn trở nên cực đoan hơn. Như đã được giải thích trong các nghiên cứu trước, đây chính xác là mẫu hình được kỳ vọng (và đã được quan sát) nếu xác suất chuyển đổi theo từng thời điểm là ổn định, như trong các quá trình Markov hai trạng thái đơn giản (Heyman, 1979, 1982).
Do đó, mối quan hệ giữa sự thay đổi chú ý theo từng thời điểm và sự phân bổ chú ý tổng thể tuân theo cùng một quy luật định lượng như đã được quan sát trong các nghiên cứu hành vi, nơi xác suất chuyển đổi từ một nguồn thức ăn sang nguồn khác là tương đối ổn định theo thời gian.
Kiểm định các giả định chính
Chúng tôi giả định rằng trong mỗi trial:
(1) các báo cáo tự khai của người tham gia phản ánh trung thực kích thích mà họ đã chú ý,
(2) nếu người tham gia chú ý vào một kích thích, họ sẽ cộng chính xác các chữ số, và
(3) người tham gia không có thông tin hữu ích về kích thích mà họ không chú ý.
Các kết quả đã ủng hộ những giả định này. Trong các trial không có cue, tỷ lệ chính xác đạt 95% đối với kích thích mà người tham gia cho biết họ đã chú ý. Ngược lại, tỷ lệ chính xác gần với mức ngẫu nhiên (15.0% so với 14.3%) trong các trial mà chú ý được phân bổ vào kích thích không cung cấp thông tin đúng.
Những con số này rất gần với hiệu suất của một người tham gia “lý tưởng”, tức là trong mỗi trial chỉ chú ý vào một kích thích, cộng chính xác ba chữ số, nhưng không xử lý kích thích còn lại.
Các kết quả này cũng tái hiện những phát hiện trước đây của chúng tôi (Heyman và cộng sự, 2016). Trong nghiên cứu ban đầu, tỷ lệ đoán đúng là 16.2% và tỷ lệ các trial mà người tham gia xác định đúng tổng ba chữ số trong các trial có cue là 90%. Tuy nhiên, khác với thí nghiệm hiện tại, tỷ lệ đoán đúng khi đó là một nghiệm của mô hình toán học dùng để tính toán sự phân bổ chú ý. Nói cách khác, tỷ lệ đoán đúng được xác định bằng tự báo cáo và tỷ lệ đoán đúng được suy ra từ mô hình toán học chỉ khác nhau trung bình không quá 1.2%.
Liên hệ với các nghiên cứu trước
Các thước đo về phân bổ chú ý tổng thể (xem Hình 2) và tần suất chuyển đổi chú ý giữa hai kích thích theo từng trial tái hiện rất sát các kết quả từ các nghiên cứu matching trong phòng thí nghiệm, bất chấp sự khác biệt về loài và loại phần thưởng. Tuy nhiên, các kết quả trong nghiên cứu này cũng có một số khác biệt nhất định so với tài liệu hành vi.
Thứ nhất, trong cả bốn điều kiện được tóm tắt ở Hình 2, hệ số chặn của phương trình matching phù hợp nhất đều mang giá trị dương. Điều này cho thấy tồn tại một thiên lệch hướng về kích thích phía trên. Ví dụ, trong điều kiện 1:1, tỷ lệ phân bổ trung bình là 1.28/1.00, mặc dù xác suất được lập trình để kích thích phía trên là mục tiêu hoàn toàn bằng với kích thích phía dưới (1:1).
Trong các nghiên cứu hành vi, hệ số chặn khác 0 thường phản ánh thiên lệch vị trí hoặc sự khác biệt về chất lượng phần thưởng. Trong thí nghiệm này, không có “hai phía” theo nghĩa vật lý rõ ràng hoặc phần thưởng cụ thể có thể khác nhau. Tuy nhiên, trong các nghiên cứu nhận thức sử dụng các ma trận kích thích được trình bày trong thời gian ngắn (ví dụ ma trận 2 × 4), người tham gia có xu hướng báo cáo các phần tử từ hàng đầu tiên nhiều hơn (Sperling, 1960; Lass và cộng sự, 2008), và hiện tượng này được cho là liên quan đến thói quen đọc.
Cách giải thích này phù hợp với các hướng nghiên cứu gần đây nhấn mạnh rằng trong cả môi trường phòng thí nghiệm lẫn đời sống hàng ngày, chú ý được dẫn dắt bởi nhiều yếu tố, bao gồm các khuôn mẫu nhận thức tiềm ẩn lâu dài, chẳng hạn như việc đọc văn bản từ trên xuống dưới.
Thứ hai, trong các trial mà người tham gia báo cáo chú ý vào kích thích không phải mục tiêu, họ trả lời đúng khoảng 15% số trial. Kết quả này gần với tỷ lệ đoán ngẫu nhiên kỳ vọng (1/7), cho thấy người tham gia hầu như không có thông tin hữu ích về kích thích không được chú ý.
Điều này phù hợp với các mô hình chú ý kiểu “winner-take-all” (tức là chỉ một kích thích được xử lý hiệu quả). Tuy nhiên, như đã đề cập trong phần Hạn chế, có lý do để tin rằng đặc điểm “winner-take-all” này xuất hiện hoặc do việc lặp lại nhiều lần quy trình, hoặc ở giai đoạn xử lý nhận thức muộn khi người tham gia đưa ra lựa chọn trong màn hình trả lời.
Hạn chế
Như đã đề cập trong phần mở đầu, quy trình và các phép đo của chúng tôi không xác định được vị trí chính xác của các ràng buộc nhận thức. Nếu chỉ xét riêng các kết quả, chúng phù hợp với cả các mô hình chú ý nhấn mạnh quá trình lựa chọn sớm (early selection) lẫn các mô hình nhấn mạnh lựa chọn muộn (late selection).
Tuy nhiên, tài liệu nghiên cứu cho thấy khả năng cao hơn là các quá trình lựa chọn muộn đóng vai trò quan trọng hơn. Thứ nhất, trong một nghiên cứu được trích dẫn rộng rãi sử dụng các kích thích có kích thước tương tự như trong nghiên cứu này, Eriksen và Hoffman (1973) đã tìm thấy bằng chứng cho thấy tồn tại một giới hạn không thể giảm hơn nữa về “kích thước” của vùng chú ý, tương ứng với khoảng 1 độ góc nhìn. Nếu điều này đúng, thì không chỉ ánh nhìn mà cả chú ý không gian thị giác cũng bao trùm cả hai kích thích ngay từ giai đoạn trình bày ban đầu.
Thứ hai, nhiều nghiên cứu cho thấy trong các nhiệm vụ chú ý đơn giản (như nhận diện một chữ cái hoặc một đường nghiêng), người tham gia có thể chú ý đồng thời đến hai vị trí không gian cách xa nhau hơn so với hai kích thích trong nghiên cứu này.
Do đó, có cơ sở để cho rằng trong nghiên cứu này, người tham gia có khả năng chú ý đến cả hai kích thích trong giai đoạn hiển thị ban đầu. Vậy tại sao họ lại không có thông tin hữu ích về kích thích không được chú ý khi đưa ra phản hồi?
Giải thích đơn giản nhất là kích thích không được chú ý không được mã hóa đầy đủ hoặc đã bị mất khỏi trí nhớ làm việc trong quá trình xử lý kích thích được chú ý (ví dụ khi thực hiện phép cộng).
Ngoài ra, khi người tham gia học được kích thích nào có khả năng là mục tiêu cao hơn, các cơ chế ức chế hoặc kìm hãm có thể được kích hoạt, làm hạn chế việc xử lý sớm của kích thích không được chú ý. Ví dụ, các phương pháp priming có thể cho thấy một số thông tin về kích thích không được chú ý, đặc biệt trong các trial đầu của phiên đầu tiên.
Một hướng nghiên cứu khác là kiểm tra liệu các phương pháp trình bày chuỗi kích thích nhanh (rapid serial visual presentation), trong đó đặc điểm thống kê của kích thích chứ không phải tín hiệu trực quan báo hiệu mục tiêu, có tạo ra kết quả tương tự hay không, và liệu sự khác biệt (nếu có) có phụ thuộc vào mức độ luyện tập hay không.
Một hạn chế mang tính tổng quát hơn là điểm chung của hầu hết các nghiên cứu về định luật matching. Trong quy trình hiện tại, cũng như trong các quy trình thông thường nơi khả năng nhận phần thưởng là liên tục, xác suất nhận phần thưởng thay đổi theo thời gian như một hàm của các lựa chọn gần nhất. Tuy nhiên, các động lực này không được mô hình hóa trong các phương trình (1) và (2), và thường cũng không được đề cập trong các báo cáo nghiên cứu.
Các nghiên cứu theo dõi trực tiếp hành vi theo từng thời điểm cho thấy rất ít hoặc không có bằng chứng về việc theo dõi xác suất phần thưởng theo thời gian. Thậm chí, trong một trường hợp, một mô hình Markov hai trạng thái đơn giản đã mô tả tốt dữ liệu. Do đó, chưa rõ liệu các phân tích vi mô hơn có mang lại lợi ích hay không.
Kết luận
Định luật Matching ban đầu được xây dựng như một bản tóm tắt định lượng về mối quan hệ giữa hành vi tự nguyện và hậu quả của nó. Trong các nghiên cứu ban đầu, hậu quả là các phần thưởng cụ thể như thức ăn cho động vật.
Trong thí nghiệm này, hậu quả là cảm nhận chủ quan của người tham gia rằng họ đã đưa ra câu trả lời đúng và không có phản hồi trực tiếp từ môi trường. Theo tiêu chuẩn của các nghiên cứu hành vi, những cảm nhận này vẫn có thể đóng vai trò như phần thưởng.
Điều này gợi ý rằng sự tự đánh giá tích cực ( tôi đã tính đúng tổng ) có chức năng tương tự như các phần thưởng vật lý từ môi trường. Từ đó, có thể suy ra rằng các trạng thái tích cực nội tại và các sự kiện mang tính thưởng bên ngoài có thể chia sẻ những cơ chế nền tảng chung.
Việc phân bổ nguồn lực nhận thức và phân bổ hành vi đều liên quan đến bài toán quản lý nguồn lực hạn chế. Do đó, nếu định luật matching mô tả sự phân bổ lựa chọn, thì nó cũng có thể mô tả cách con người phân bổ chú ý giữa các kích thích cạnh tranh.
Các kết quả trong nghiên cứu này ủng hộ mạnh mẽ lập luận này: định luật matching mô tả sự phân bổ các quá trình nhận thức ẩn chính xác tương tự như cách nó mô tả các hành vi quan sát được.
Điều còn lại cần xác định là bản chất của các ràng buộc nhận thức khiến người tham gia chỉ có thể trả lời đúng một trong hai kích thích trong mỗi trial. Những ràng buộc này xảy ra ở giai đoạn xử lý ban đầu, trong quá trình tính toán, hay ở cả hai? Và ở giai đoạn nào chúng vận hành theo đúng dự đoán của định luật matching?
Trả lời những câu hỏi này sẽ không hề đơn giản. Tuy nhiên, trước khi thực hiện nghiên cứu này, chúng tôi thậm chí còn chưa nhận ra rằng những câu hỏi đó cần được đặt ra.
Kết luận mở rộng
Nghiên cứu này mở rộng đáng kể phạm vi ứng dụng của định luật Matching khi cho thấy nguyên tắc vốn được xây dựng để mô tả hành vi có thể quan sát được cũng có khả năng giải thích sự phân bổ của các quá trình nhận thức tiềm ẩn, đặc biệt là sự chú ý. Kết quả thực nghiệm cho thấy sự phân bổ chú ý giữa hai kích thích tuân theo cùng một quy luật định lượng như sự phân bổ lựa chọn trong các thí nghiệm hành vi, với mức độ giải thích phương sai rất cao (từ 95% đến 99%), qua đó củng cố mạnh mẽ giả thuyết rằng các cơ chế nền tảng điều khiển hành vi và nhận thức có thể chia sẻ một cấu trúc chung . Điều này có ý nghĩa lý thuyết sâu sắc vì nó thách thức sự phân tách truyền thống giữa tâm lý học nhận thức và tâm lý học hành vi, gợi ý rằng thay vì tồn tại như hai hệ thống độc lập, nhận thức và hành vi có thể được hiểu như các biểu hiện khác nhau của cùng một quá trình phân bổ nguồn lực hạn chế. Trong bối cảnh này, chú ý không còn đơn thuần là một quá trình tri giác thụ động, mà trở thành một dạng “lựa chọn nội tại” (internal choice), nơi hệ thống nhận thức phải liên tục tối ưu hóa việc phân bổ tài nguyên dựa trên các tín hiệu giá trị tương đối của môi trường.
Một điểm đáng chú ý là mặc dù không có phần thưởng vật lý rõ ràng trong thí nghiệm, người tham gia vẫn thể hiện hành vi phù hợp với dự đoán của định luật Matching, cho thấy rằng các cơ chế củng cố không nhất thiết phải phụ thuộc vào các kích thích bên ngoài hữu hình. Thay vào đó, cảm nhận chủ quan về việc “trả lời đúng” có thể đóng vai trò như một dạng phần thưởng nội tại, qua đó mở rộng khái niệm reinforcement sang lĩnh vực nhận thức . Điều này phù hợp với các lý thuyết hiện đại về học tăng cường (reinforcement learning), trong đó tín hiệu lỗi dự đoán (prediction error) có thể được tạo ra không chỉ từ phần thưởng bên ngoài mà còn từ các trạng thái nội tại như sự hài lòng nhận thức hoặc cảm giác chính xác. Hệ quả là, ranh giới giữa động lực ngoại sinh và nội sinh trở nên mờ nhạt, và các quá trình nhận thức như chú ý có thể được điều chỉnh bởi cùng một nguyên tắc tối ưu hóa như hành vi.
Tuy nhiên, mặc dù mô hình Matching mô tả tốt dữ liệu ở mức tổng thể, nghiên cứu cũng chỉ ra một số sai lệch có hệ thống, chẳng hạn như thiên lệch ưu tiên kích thích ở vị trí phía trên. Hiện tượng này không thể được giải thích bằng sự khác biệt về phần thưởng, mà nhiều khả năng liên quan đến các yếu tố nhận thức bậc cao như thói quen đọc hoặc cấu trúc xử lý thông tin đã được học trước đó . Điều này cho thấy rằng mặc dù định luật Matching có tính khái quát cao, nó vẫn chịu ảnh hưởng bởi các thiên lệch nhận thức nền tảng, và do đó không nên được xem như một mô hình hoàn toàn độc lập với bối cảnh. Nói cách khác, Matching cung cấp một khung mô tả mạnh mẽ, nhưng cần được tích hợp với các yếu tố như prior experience, attentional bias và cấu trúc nhận thức dài hạn để giải thích đầy đủ hành vi.
Ngoài ra, kết quả về sự chuyển đổi chú ý theo từng trial cho thấy một mẫu hình tương đồng đáng kinh ngạc với các nghiên cứu trên động vật, trong đó tần suất chuyển đổi đạt cực đại khi phân bổ chú ý gần mức cân bằng và giảm dần khi sự phân bổ trở nên cực đoan . Mẫu hình này phù hợp với các mô hình Markov hai trạng thái, gợi ý rằng sự chuyển đổi chú ý có thể được điều khiển bởi các quy luật xác suất đơn giản thay vì các quá trình nhận thức phức tạp hơn. Điều này có ý nghĩa quan trọng vì nó cho thấy rằng ngay cả các quá trình nhận thức cấp cao như chú ý cũng có thể được mô tả bằng các nguyên tắc toán học tương đối đơn giản, tương tự như hành vi động vật, từ đó củng cố quan điểm về tính liên tục giữa các hệ thống sinh học.
Tuy nhiên, nghiên cứu cũng để lại một số câu hỏi mở quan trọng liên quan đến bản chất của các ràng buộc nhận thức. Cụ thể, chưa rõ liệu giới hạn khiến người tham gia chỉ có thể xử lý một kích thích trong mỗi trial xuất phát từ giai đoạn xử lý sớm (perceptual encoding), giai đoạn xử lý muộn (working memory hoặc decision-making), hay sự kết hợp của cả hai . Việc phân biệt giữa các khả năng này có ý nghĩa quan trọng đối với việc xây dựng các mô hình lý thuyết về chú ý, đặc biệt trong bối cảnh tranh luận lâu dài giữa các mô hình lựa chọn sớm và lựa chọn muộn. Ngoài ra, khả năng tồn tại các cơ chế ức chế hoặc ưu tiên dựa trên kinh nghiệm cũng gợi ý rằng sự phân bổ chú ý không chỉ là phản ứng thụ động với xác suất môi trường, mà còn là kết quả của quá trình học và thích nghi theo thời gian.
Tổng thể, nghiên cứu này cung cấp bằng chứng thuyết phục rằng định luật Matching có thể được xem như một nguyên tắc lựa chọn tổng quát, áp dụng không chỉ cho hành vi quan sát được mà còn cho các quá trình nhận thức tiềm ẩn. Tuy nhiên, để hiểu đầy đủ cơ chế này, cần có các nghiên cứu tiếp theo nhằm làm rõ vai trò của các yếu tố như ràng buộc nhận thức, kinh nghiệm tích lũy và tương tác giữa các cấp độ xử lý thông tin. Việc tích hợp các cách tiếp cận từ tâm lý học hành vi, khoa học nhận thức và khoa học thần kinh sẽ là hướng đi cần thiết để xây dựng một lý thuyết thống nhất về cách con người phân bổ nguồn lực hạn chế trong cả hành vi và nhận thức.
Tham khảo
Anderson, B. A., & Yantis, S. (2013). Persistence of value-driven attentional capture. Journal of Experimental Psychology: Human Perception and Performance, 39, 6 –9. http://dx.doi.org/10.1037/a0030860
Arvanitogiannis, A., & Shizgal, P. (2008). The reinforcement mountain: Allocation of behavior as a function of the rate and intensity of reward-
ing brain stimulation. Behavioral Neuroscience, 122, 1126 –1138. http://dx.doi.org/10.1037/a0012679
Baum, W. M. (1974). On two types of deviation from the matching law: Bias and undermatching. Journal of the Experimental Analysis of Behavior, 22, 231–242. http://dx.doi.org/10.1901/jeab.1974.22-231
Baum, W. M. (1979). Matching, undermatching, and overmatching in studies of choice. Journal of the Experimental Analysis of Behavior, 32,269 –281. http://dx.doi.org/10.1901/jeab.1979.32-269
Bay, M., & Wyble, B. (2014). The benefit of attention is not diminished when distributed over two simultaneous cues. Attention, Perception &
Psychophysics, 76, 1287–1297. http://dx.doi.org/10.3758/s13414-014-0645-z
Borrero, J. C., & Vollmer, T. R. (2002). An application of the matching law to severe problem behavior. Journal of Applied Behavior Analysis, 35, 13–27. http://dx.doi.org/10.1901/jaba.2002.35-13
Bridwell, D. A., & Srinivasan, R. (2012). Distinct attention networks for feature enhancement and suppression in vision. Psychological Science, 23, 1151–1158. http://dx.doi.org/10.1177/0956797612440099
Cero, I., & Falligant, J. M. (2020). Application of the generalized matching law to chess openings: A gambit analysis. Journal of Applied Behavior
Analysis, 53, 835– 845. http://dx.doi.org/10.1002/jaba.612
Chelazzi, L., Bisley, J. W., & Bartolomeo, P. (2018). The unconscious guidance of attention. Cortex, 102, 1–5. http://dx.doi.org/10.1016/j.cortex.2018.02.002
Chelazzi, L., Perlato, A., Santandrea, E., & Della Libera, C. (2013). Rewards teach visual selective attention. Vision Research, 85, 58 –72.
http://dx.doi.org/10.1016/j.visres.2012.12.005
Conger, R., & Killeen, P. (1974). Use of concurrent operants in small group research: A demonstration. Pacific Sociological Review, 17, 399 –416. http://dx.doi.org/10.2307/1388548
Corbetta, M., Miezin, F. M., Dobmeyer, S., Shulman, G. L., & Petersen, S. E. (1990). Attentional modulation of neural processing of shape, color, and velocity in humans. Science, 248, 1556 –1559. http://dx.doi.org/10.1126/science.2360050
Davison, M., & McCarthy, D. (1988). The matching law: A research review. Hillsdale, NJ: Lawrence Erlbaum.
De Carlo, L. T., & Abramson, C. I. (2012). “Time allocation in carpenterants (Camponotus herculeanus)”: Correction to De Carlo & Abramson (1989). Journal of Comparative Psychology, 126, 346. http://dx.doi.org/10.1037/a0030304
De Cesarei, A., & Codispoti, M. (2008). Fuzzy picture processing: Effects of size reduction and blurring on emotional processing. Emotion, 8, 352–363. http://dx.doi.org/10.1037/1528-3542.8.3.352
Duncan, J. (1980). The locus of interference in the perception of simultaneous stimuli. Psychological Review, 87, 272–300. http://dx.doi.org/10.1037/0033-295X.87.3.272
Eriksen, C. W., & Hoffman, J. E. (1973). The extent of processing of noise elements during selective encoding from visual displays. Perception & Psychophysics, 14, 155–160. http://dx.doi.org/10.3758/BF03198630
Falligant, J. M., Boomhower, S. R., & Pence, S. T. (2016). Application of the generalized matching law to point-after-touchdown conversions and kicker selection in college football. Psychology of Sport and Exercise, 26, 149 –153. http://dx.doi.org/10.1016/j.psychsport.2016.07.006
Foxall, G. R., James, V. K., Oliveira-Castro, J. M., & Ribier, S. (2010). Product substitutability and the matching law. The Psychological Record, 60, 185–216. http://dx.doi.org/10.1007/BF03395703
Goolkasian, P. (1991). The effect of size on the perception of ambiguous figures. Bulletin of the Psychonomic Society, 29, 161–164. http://dx.doi.org/10.3758/BF03335224
Grace, R. C., & Hucks, A. D. (2013). The allocation of operant behavior. In G. J. Madden, W. V. Dube, T. D. Hackenberg, G. P. Hanley, & K. A.
Lattal (Eds.), APA handbook of behavior analysis, Vol. 1: Methods and principles (pp. 307–337). Washington, DC: American Psychological
Association. http://dx.doi.org/10.1037/13937-014
Gray, L. N., Stafford, M. C., & Tallman, I. (1991). Rewards and punishments in complex human choices. Social Psychology Quarterly, 54, 318 –329. http://dx.doi.org/10.2307/2786844
Herrnstein, R. J. (1970). On the law of effect. Journal of the Experimental Analysis of Behavior, 13, 243–266. http://dx.doi.org/10.1901/jeab.1970.13-243
Herrnstein, R. J., Rachlin, H., & Laibson, D. I. (Eds.). (1997). The matching law: Papers in psychology and economics. Cambridge, MA: Harvard University Press.
Heyman, G. M. (1979). A Markov model description of changeover probabilities on concurrent schedules. Journal of the Experimental Analysis of Behavior, 31, 41–51. http://dx.doi.org/10.1901/jeab.1979.31-41
Heyman, G. M. (1982). Is time allocation elicited behavior? In M. Commons, R. Herrnstein, & H. Rachlin (Eds.), Quantitative analyses of behavior: Vol. 2.Matching and maximizing accounts (pp. 459 – 490).
Cambridge, MA: Ballinger Press. Heyman, G. M., Grisanzio, K. A., & Liang, V. (2016). Introducing a method for calculating the allocation of attention in a cognitive “two-armed bandit” procedure: Probability matching gives way to maximizing. Frontiers in Psychology, 7, 223. http://dx.doi.org/10.3389/fpsyg
.2016.00223
Heyman, G. M., & Luce, R. D. (1979). Operant matching is not a logical consequence of reinforcement rate maximization. Animal Learning & Behavior, 7, 133–140. http://dx.doi.org/10.3758/BF03209261
Heyman, G. M., Montemayor, J., & Grisanzio, K. A. (2017). Dissociating attention and eye movements in a quantitative analysis of attention allocation. Frontiers in Psychology, 8, 715. http://dx.doi.org/10.3389/fpsyg.2017.00715
Houston, A. (1986). The matching law applies to wagtails’ foraging in the wild. Journal of the Experimental Analysis of Behavior, 45, 15–18. http://dx.doi.org/10.1901/jeab.1986.45-15
Houston, A. I., McNamara, J. M., & Steer, M. D. (2012). Do we expect natural selection to produce rational behaviour? In A. K. Seth, T. J.
Prescott, & J. J. Bryson (Eds.), Modelling natural action selection (pp.12–36). New York, NY: Cambridge University Press.
Jiang, Y. V. (2018). Habitual versus goal-driven attention. Cortex, 102, 107–120. http://dx.doi.org/10.1016/j.cortex.2017.06.018
Jonides, J. (1983). Further toward a model of the mind’s eye’s movement.
Bulletin of the Psychonomic Society, 21, 247–250. http://dx.doi.org/10.3758/BF03334699
Kubanek, J. (2017). Optimal decision making and matching are tied through diminishing returns. Proceedings of the National Academy of Sciences of the United States of America, 114, 8499 – 8504. http://dx.doi.org/10.1073/pnas.1703440114
Lass, U., Yan, S., Chen, G., Becker, D., & Lüer, G. (2008). Position effects in encoding briefly exposed item matrices: Evidence for a reading bias or merely a matter of the selection criterion? Psychological Research, 72, 641– 647. http://dx.doi.org/10.1007/s00426-008-0169-z
Lavie, N., Hirst, A., de Fockert, J. W., & Viding, E. (2004). Load theory of selective attention and cognitive control. Journal of Experimental Psychology: General, 133, 339 –354. http://dx.doi.org/10.1037/0096-3445.133.3.339
Lee, J., & Shomstein, S. (2014). Reward-based transfer from bottom-up to top-down search tasks. Psychological Science, 25, 466 – 475. http://dx.doi.org/10.1177/0956797613509284
Le Pelley, M. E., Vadillo, M., & Luque, D. (2013). Learned predictiveness influences rapid attentional capture: Evidence from the dot probe task.
Journal of Experimental Psychology: Learning, Memory, and Cognition, 39, 1888 –1900. http://dx.doi.org/10.1037/a0033700
Loewenstein, Y., Seung, H. S., & Newsome, W. T. (2006). Operant matching is a generic outcome of synaptic plasticity based on the covariance between reward and neural activity. Proceedings of the National Academy of Sciences of the United States of America, 103, 15224 –15229. http://dx.doi.org/10.1073/pnas.0505220103
Nevin, J. A. (1969). Interval reinforcement of choice behavior in discrete trials. Journal of the Experimental Analysis of Behavior, 12, 875– 885. http://dx.doi.org/10.1901/jeab.1969.12-875
Raymond, J. E., & O’Brien, J. L. (2009). Selective visual attention and motivation: The consequences of value learning in an attentional blink task. Psychological Science, 20, 981–988. http://dx.doi.org/10.1111/j.1467-9280.2009.02391.x
Rees, C., & Winfree, L. T., Jr. (2017). Social learner decision making: Matching theory as a unifying framework for recasting a general theory. In W. Bernasco, J.-L. Van Gelder, & H. Elffers (Eds.), The Oxford handbook of offender decision making (pp. 268 –300). New York, NY: Oxford University Press.
Shahan, T. A., & Podlesnik, C. A. (2006). Divided attention performance and the matching law. Learning & Behavior, 34, 255–261. http://dx.doi.org/10.3758/BF03192881
Shanks, D. R., Tunney, R. J., & McCarthy, J. D. (2002). A re-examination of probability matching and rational choice. Journal of Behavioral Decision Making, 15, 233–250. http://dx.doi.org/10.1002/bdm.413
Shaw, M. L., & Shaw, P. (1977). Optimal allocation of cognitive resources to spatial locations. Journal of Experimental Psychology: Human Perception and Performance, 3, 201–211. https://doi-org.ezp-prod1.hul.harvard.edu/10.1037/0096-1523.3.2.201
Small, D. M., Gitelman, D., Simmons, K., Bloise, S. M., Parrish, T., & Mesulam, M. M. (2005). Monetary incentives enhance processing in brain regions mediating top-down control of attention. Cerebral Cortex, 15, 1855–1865. http://dx.doi.org/10.1093/cercor/bhi063
Soltani, A., & Wang, X. J. (2006). A biophysically based neural model of matching law behavior: Melioration by stochastic synapses. The Journal of Neuroscience: The Official Journal of the Society for Neuroscience, 26, 3731–3744. http://dx.doi.org/10.1523/JNEUROSCI.5159-05.2006
Sperling, G. (1960). The information available in brief visual presentations. Psychological Monographs, 74, 1–29. http://dx.doi.org/10.1037/h0093759
Todd, R. M., & Manaligod, M. G. M. (2018). Implicit guidance of attention: The priority state space framework. Cortex, 102, 121–138. http://dx.doi.org/10.1016/j.cortex.2017.08.001
Todorov, J. C., de Oliveira Castro, J. M., Hanna, E. S., Bittencourt de Sa, M. C., & Barreto, M. Q. (1983). Choice, experience, and the generalized
matching law. Journal of the Experimental Analysis of Behavior, 40, 99 –111. http://dx.doi.org/10.1901/jeab.1983.40-99
Treisman, A. M. (1969). Strategies and models of selective attention. Psychological Review, 76, 282–299. http://dx.doi.org/10.1037/h0027242
Vollmer, T. R., & Bourret, J. (2000). An application of the matching law to evaluate the allocation of two- and three-point shots by college basketball players. Journal of Applied Behavior Analysis, 33, 137–150. http://dx.doi.org/10.1901/jaba.2000.33-137
Wandell, B. A. (1995). Foundations of vision. Sunderland, MA: Sinauer Associates.
Wolfe, J. M. (1992). The parallel guidance of visual attention. Current Directions in Psychological Science, 1, 124 –128. http://dx.doi.org/10.1111/1467-8721.ep10769733
Wühr, P., & Frings, C. (2008). A case for inhibition: Visual attention suppresses the processing of irrelevant objects. Journal of Experimental Psychology: General, 137, 116 –130. http://dx.doi.org/10.1037/0096-3445.137.1.116
Zénon, A., Ben Hamed, S., Duhamel, J.-R., & Olivier, E. (2009). Attentional guidance relies on a winner-take-all mechanism. Vision Research, 49, 1522–1531. http://dx.doi.org/10.1016/j.visres.2009.03.010